A Practical Guide to A/B Testing
May 15, 2020 · 6 min · Data Science
I spent a lot of time on A/B testing during my time as a data scientist at Squarespace. A lot of people shrug off experimentation as "analyst-work" and don't get super excited about it. For me, A/B testing was a way to be more involved in product development and have a material impact on what gets shipped. Honestly, I really enjoyed it.
I came to a realization early on that there's a dramatic mismatch between what you learn in statistics textbooks and how experimentation works in practice. Being successful at A/B testing doesn't come down to analytical methods. It's about process and people.
Know What Test You're Running
This isn't about t-tests or z-tests. It's not about Bayesian vs. frequentist methods. There are different kinds of A/B tests beyond how you choose to evaluate results. First and foremost, you have to set the context for the experiment. Uncertainty before the test leads to incorrect decisions after the test.
There are three bins that good A/B tests fall into: Big bets, health checks, and iterative. Let's talk about big bets first. These are tests where you expect a large impact on your primary metric, one way or another. There may be some assumption driving this experiment that is still unproven. Here's the kicker: If there isn't a significant difference between variant and control, you'll defer to control. Shipping features that don't provide impact leads to a cluttered product and wasted time maintaining that code.
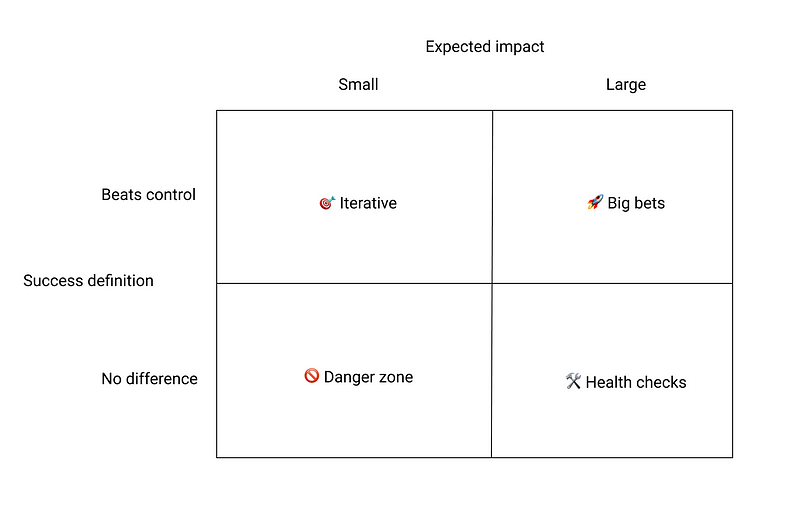
Like big bets, health checks are pretty large changes in the product. Where they differ, is in the context of the test. These are new features or big product changes that you want to roll out. They may be the minimum viable version of a larger initiative within the organization or maybe they just provide a better experience for the user. You don't need to detect a significant difference to ship these changes. You just need to ensure that they don't meaningfully hurt metrics.
One clever way to think about these tests, is that the first version represents the "floor" of what this variant could be. Of course, this is contingent on follow-up work streams. If there is no vision for "next steps" then that's a red flag that you might be mistaking a big bet for a health check.
The last bin that good A/B tests fall into is iterative. When most people think of A/B testing, this is what comes to mind. This is the 50 shades of blue example that we know and love. Don't expect a huge impact from these tests, but they can be powerful if you have enough traffic. It's worth noting that this is a big "if" for most organizations. Take power analysis seriously here. If the test is going to take 2 months to run, then it isn't high leverage enough to merit an A/B test. There is lower hanging, more impactful fruit out there.
There is one more quadrant in the visualization above that I didn't touch on. The danger zone is when you expect a small impact on your primary metric, but are willing to roll it out even when there's no significant difference. If you are Google, maybe this makes sense. If you aren't Google, this is an unnecessary precaution and will take up bandwidth that results in no actionable results. I normally suggest that tests in this bucket are rolled out initially, and then metrics are monitored afterward, just to be safe.
Get Everything Down in Writing
There are plenty of reasons why you want to get everything down in writing before kicking off an A/B test. This isn't a novel suggestion, but it's also the root cause of so many common missteps that I had to mention it.
Running an A/B test at scale is a cross-functional endeavor. Chances are it will involve Data Science and Analytics, Product, Engineering, and potentially Design as well. With all of these different touchpoints, you need a "source of truth" document. This is something that you can point people to for sufficient context.
Another benefit of putting things down on paper before the test — It helps you avoid bias. The product owner should clearly state their assumptions and hypotheses for running the test. This is helpful for others to review and ensure they understand. It's also nice to have after the test is complete so you can easily check whether the hypotheses were validated or rejected.
Lastly, documentation is key. Keeping a running log of these A/B test documents in a centralized, searchable place will pay huge dividends later on. This turns into a knowledge base for everything you have learned while building products. Veterans on the team will reference it for product insights and newcomers will be able to build out their understanding of the product much more quickly.
Choose Your Primary Metric
Related to the last point of writing things down, you should state what metrics you care about before the test. I like breaking these up into primary, secondary, and "will monitor" in most cases.
Where a lot of people go wrong is that they want to track too many metrics. It's okay to have a laundry list of secondary and "will monitor" metrics, but you can only have one primary metric. This is your main decision criteria. If you try to balance the tradeoffs between multiple data points here, you will be biased to twist the data around in a way that favors your preconceptions.
This seems straightforward, but it can be difficult. What if you are running a checkout optimization test and you find that the variant improves the number of conversions, but lowers the average purchase value? How do you deal with these conflicting variables? There are lots of considerations, but having a unified view upfront about which metric matters most will make your life easier come decision time.
Partner With Engineering Where Needed
I'm not sure how A/B testing infrastructure is set up at your organization. I've found that it varies greatly from company to company. There are huge tech companies that have everything baked in and then there are smaller startups where it's the wild west. If you aren't the former, assignment logic is never as easy as it seems.
You should spec out in the written document who is being assigned, what unique id they are being assigned on, and when that assignment is occurring. This complexity needs to be handled if your infrastructure doesn't handle it for you. You may need to partner with engineering to get things implemented in the right way. It's not the most interesting work in the world, but it's worth investing the time and effort to get this right. Otherwise, you'll find yourself trying to stitch together broken assignments come evaluation time, and you won't have a good time.
Turn Insights Into Tests
So, you have finally run the test and waited patiently for results. This is where things get exciting! Oddly enough, data scientists get lazy here. They report on the key metrics, name the winning variant, and call it a day. This is a missed opportunity!
The most interesting parts of an A/B test are buried in the analysis. This is where you learn about how people use your product. You should write up this analysis and share it with everyone involved in the testing process as part of your reporting. This analysis will often surface other hypotheses that will lead to more tests and so on. This is the cyclical nature of experimentation.
The fundamental activity of a startup is to turn ideas into products, measure how customers respond, and then learn whether to pivot or persevere. All successful startup processes should be geared to accelerate that feedback loop. — Eric Ries
Productize Your Thinking
When your organization reaches a certain scale, you will hit this weird middle ground where you have a data science team that is ready to work on more specialized problems, but A/B testing is still taking up a disproportionate amount of time. What do you do here?
If you want to democratize A/B testing across your org, then you need to productize your thinking. You hear stories of tools at Airbnb and Facebook that employees can use to launch and evaluate test, all self-serve. This is a great example of taking data science processes and encapsulating them into a tool that anyone can use. It's a tough transition to get here both technically and culturally, but it's a transition that you'll have to make one day. It should be on your mind, ideally before it's already too late.
Parting Thoughts
I mentioned earlier that A/B testing is a cross-functional endeavor. Like any team sport, you sometimes have to compromise for the greater good. It may mean presenting results in a less accurate, more understandable way. It may mean spending more time before a test to write down your thought process. It may mean piecing together broken assignment data after test launch.
These tradeoffs are happening with every test. You can ignore them, or acknowledge that they exist and work together to get to the best place possible. When you do the latter, it ends up being really rewarding.
Shoutout to Josh Laurito, Greg Allen, Andrew Bartholomew, and everyone else on Data Science and Growth at Squarespace that I worked with while slowly but surely picking this stuff up.
Thanks for reading! If you enjoyed this post and you’re feeling generous, perhaps like or retweet the thread on Twitter. You can also subscribe in the form below to get future posts straight to your inbox. 🔥