Towards Modern Data Apps
Jan 21, 2022 · 4 min · Data Science
It’s no secret that our work apps are getting more and more data-centric. This has been happening gradually over the years, but recently it feels like now some especially interesting things are coming to fruition in the space. We’ve heard about The Modern Data Stack. We’ve heard about The Future of Work. But what happens when they meet?
The current state
Before speculating on what the future might look like, it’s important to take note of how we got where we are right now:
- Siloed data: Your data lived in independent apps and if you wanted to interface with it elsewhere then you better write your own ETL process to support it.
- ETL: Products like Stitch and Fivetran came along and made it much easier to get data out of different apps and into your data warehouse. “Pulling” useful data is now much easier.
- Integrations: Data in one app should be able to interact with other apps. Teams lean on APIs to build functionality for each product use case. “Pushing” data to other apps in order to make something happen is now more common.
- Reverse ETL: Product like Hightouch and Census have entered the chat. The data warehouse has established itself as the centerpiece of the data stack. Pushing data from it to other applications is in more demand now than ever.
Now we’re up to date. What does this look like exactly? You’ve probably seen this chart a million times but let me add another iteration to the mix:
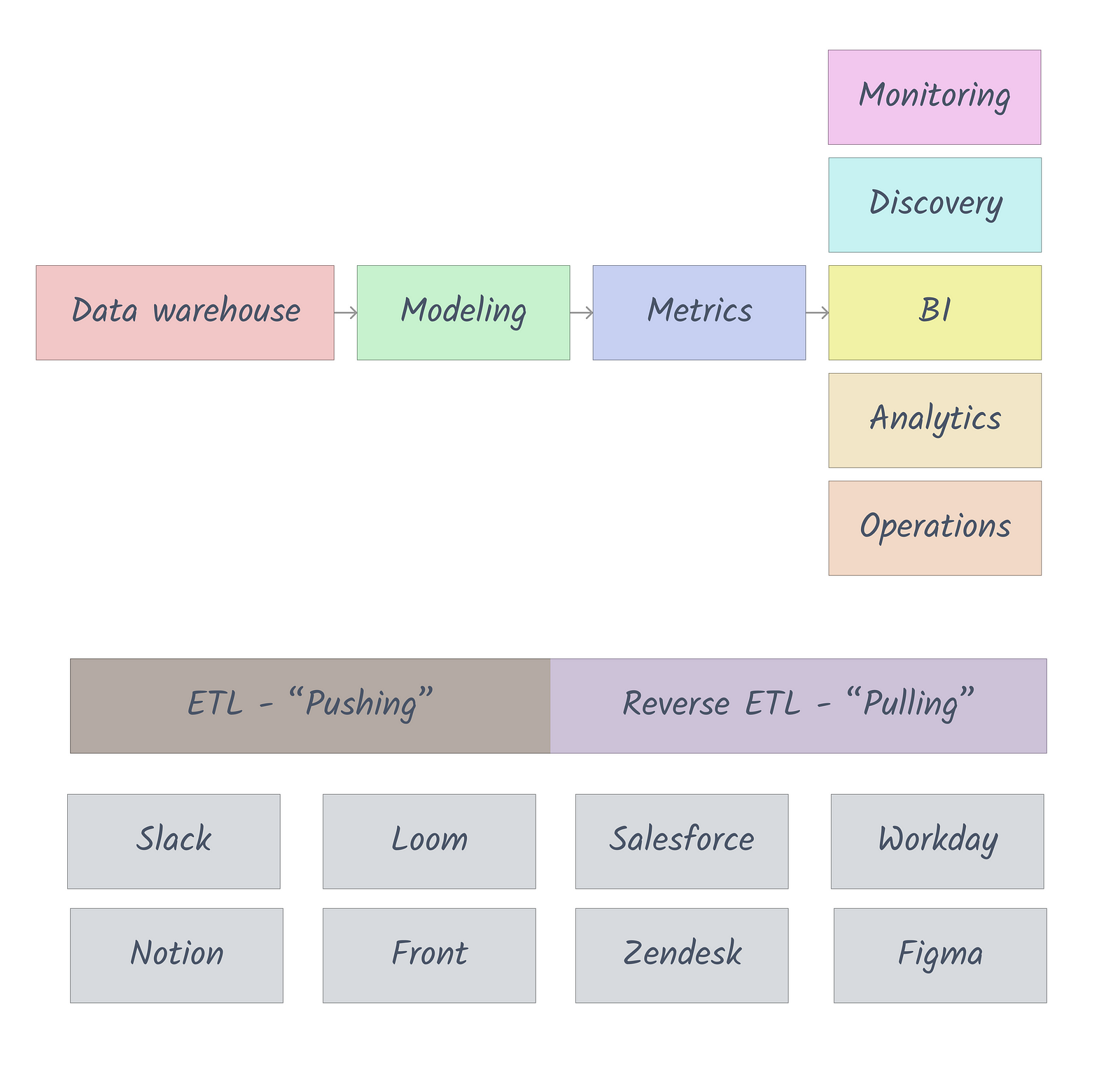
At the top, you can see the data stack and its core use cases modeled out. Below, we introduce work apps and show the primary means of pushing and pulling data to and from them: ETL and Reverse ETL. I’ve intentionally left out integrations, since they aren’t usually dealing with raw data and are centered around specific use cases.
What’s next?
There are a number of possibilities as to how things could shake out. It’s difficult to be confident about any one hypothesis, but the one thing I am confident about is that different products will handle this transition in different ways. For simplicities sake, consider two categories:
- Data-centric: These are apps where data (cross-functional data in particular) is or can be core to the user experience. Examples include Salesforce, Workday, and Front.
- Data-adjacent: These are apps where data, using the “records in tables” definition, might be helpful, but isn’t core to the user experience. Examples include Loom and Figma.
If you fall into the data-centric grouping above then you are more incentivized to improve the experience pulling external data into your app, enabling customers to export data back to their data warehouse. If your product is data-adjacent, then those use cases aren’t quite as important to you.
Make sense? Nothing too crazy so far. Now let’s revisit the concept of “Pushing” and “Pulling” data for each of these categories and generate some hypotheses on how each case will progress in the future:
Data-centric
- Pulling: Reverse ETL is the standard for this today. Demand for bringing cross-functional data into data-centric apps will continue to grow and eventually become table stakes. Existing apps will build this functionality into their app and sell it as a feature. Further down the line, new “data apps” will emerge that are built completely around the data warehouse.
- Pushing: This is covered sufficiently by ETL tools today. Existing tools where data would be useful elsewhere will bring this functionality into their product and sell it as a feature.
Data-adjacent
- Pulling: Per the definition of data-adjacent, there probably isn’t much of a use case for pulling in cross-functional data here. Where data is more useful, is in the case of integrations. If the raw data isn’t as useful but some action or output is, products will build out native integrations to make that happen.
- Pushing: Where it makes sense, ETL tools will cover this by enabling users to sync data to their data warehouse. One example might be pushing Slack messages to your warehouse to reinforce it as your organizational brain. Though they probably wouldn’t do this.

Let’s summarize and talk through the above image. If data is core to a product, it will bring ETL and Reverse ETL into the product and sell it as a feature (Native Functionality).
Where it makes sense, new data apps will emerge that are built on top of the data warehouse (e.g. Salesforce 2.0). Benn Stencil covers the last scenario in-depth in his though-provoking post on the subject. The simplest way to put this shift: Our apps are moving closer and closer to the data warehouse.
Products where data aren’t as core will keep chugging along much like they do today. Reverse ETL and ETL will still be important here. Integrations will still be essential.
All in all, I’m excited to see how all this shakes out over the next few years. Which parts of this post are accurate and which are totally off? We won’t know for a bit. So for now, we wait and see.
Thanks for reading! If you enjoyed this post, you can subscribe to get future ones like it delivered straight to your inbox. If Twitter is more your speed, you can follow me there as well. 🔥